




A lot of the time, people suggest a local LLM as an alternative to big AI chatbots like ChatGPT, Claude, or Gemini because it is ostensibly free. You don’t need to pay a subscription. You just download it and run it.
And although that does seem like a great benefit at first, there are other benefits involved. Another one is, of course, privacy. With a local LLM, when you’re working strictly on your computer, your material and your work don’t have to leave your computer, go to a server, and then come back. No third party collects or stores your information — it stays entirely on your device.
But all of these aside, I’ve come to appreciate local LLMs because of another advantage they provide. To put it to perspective, we must first address the elephant in the room.
5 useful things to do with a local LLM on your phone
Privacy aside, a local LLM is just really convenient.
Big AI companies will forever test and tune
The model aside, you are also the product

The idea that an AI model is a fixed piece of software on release day is an illusion. These models are live experiments. The labs behind them constantly tweak parameters behind the scenes. This includes hidden system prompt adjustments, A/B testing, and compute throttling.
The best example of this that we’ve all seen is present in ChatGPT. Occasionally, when you’re using ChatGPT, you will get two responses instead of one, and you’ll get a choice to choose which one is better. Imagine if there were a stark difference between the options, and option A was clearly superior. What would happen if they never asked you and just showed option B? That’s exactly what happens in practice.
Most of the time, each user sees a single version with a specific system prompt, parameter set, and compute level. Someone else may see something different. Instead of asking directly, the system infers satisfaction based on behavior: Did the user quit? Were they satisfied? What were the semantics of their response? All of it.
So even if you notice differences, you rarely realize you’re part of a live test. These experiments run constantly, across all users and settings. The API doesn’t shield you from this either.
Another example is Anthropic, the ethical AI company. In April 2026, they admitted to reducing compute on their models. On March 4, they silently lowered the default reasoning effort from high to medium to reduce costs and server load as new users surged. The change was noticed because the intelligence drop was significant, which forced them to revert it. But what if it went unnoticed, and you instead blamed your system? I know I have.
Every AI company does this
It’s a fact
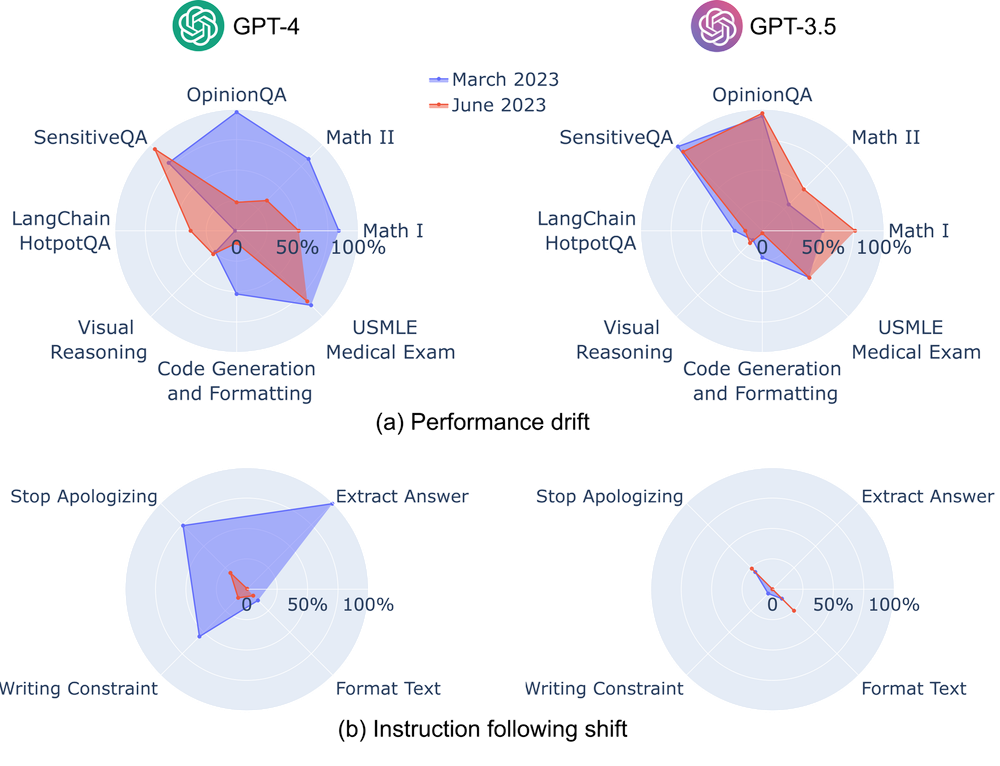
This behavior isn’t limited to one company, and it isn’t anecdotal. It’s been documented.
Researchers at Stanford and UC Berkeley wrote a paper titled How Is ChatGPT’s Behavior Changing Over Time? They systematically benchmarked OpenAI’s GPT-3.5 and GPT-4 using the exact same API endpoints over three months.
One of the tests that they ran for GPT-4 was identifying prime numbers. GPT-4’s accuracy at identifying prime numbers catastrophically dropped from 84% in March to 51% in June. So, by the time that you were using it in June, it only correctly identified the number half of the time.
Other capabilities also suffered. The model’s ability to produce directly executable code dropped significantly because the system prompt had shifted; ChatGPT increasingly favored commentary and explanation over actual coding. Multi-step reasoning was disrupted as well.
So, even though they were both called GPT-4, the March and June versions offered two very different experiences.
AI providers are running a business
Maximize. shareholders. value.

This is the reality. A new model drops — Claude Opus 5, ChatGPT 6, Gemini 4, whatever it is. Benchmarks are released, and it’s beating every other model across the board. You don’t trust the benchmark numbers, so you try the model for yourself. And yes, it’s really better. So maybe you switch back from Claude to ChatGPT, because two months ago you left ChatGPT for Claude, and now Claude’s performance has dropped. You do that. You have a great time, but then after a week… performance drops again.
Within a week, the GPT you were using at its peak isn’t the same. On release, providers show the model in its best form: all servers running at full capacity, compute limits temporarily lifted, every response optimized. The goal is to impress you and get you hooked.
Once you and I are invested — we’ve made the switch and bought our subscriptions — it’s a different story because they’ve made the sale.
This will always happen. And no LLM provider is exempt from this. Gemini, ChatGPT, Claude. They are all still running a business. And if there is a way to keep the customers and make money without spending so much of it, they will take it.
A local LLM is exempt from this
and that, is why you should switch
This is where a local LLM shines: it’s one you truly control. Yes, if you don’t have a supercomputer, it’s not going to be the same experience as a cloud AI. Even if you do have a supercomputer, it’s not going to be the same. There’s simply no way that you can match what, say, OpenAI has with all those server farms with whatever you have at home.
A local model will likely be smaller and less sharp than the latest cloud LLM at peak performance. But, it gives you stability, and with that, reliability. It runs on your machine. You control the system prompt, parameters, and compute allocation.
So even if your model is mediocre, it’s going to stay mediocre a year from now. It’s not going to change and degrade and reduce and have ups and downs. It’s going to be the same mediocre model.
For anyone serious about AI, especially when workflows depend on it, this consistency is invaluable. That’s why I’m building a proper setup to make a full switch, and why you should consider doing the same.





